Diplomarbeit - 4. Die Client-Server-Architektur
4. Die Client-Server-Architektur
Von einer Client-Server-Architektur spricht man, wenn Server und intelligente Workstations über ein Netzwerk miteinander verbunden sind. Die Client-Server-Architektur nutzt das Potential des Servers sowie das des Client Computers, um die Aufgaben im Netz zu erledigen. Dazu werden die Aufgaben folgendermaßen auf den Client und den Server verteilt. Die Serverkomponente ist unter anderem für die zentrale Datenspeicherung und Zugriffskontrollen auf die Daten verantwortlich, die Clientkomponente verarbeitet die Daten und bereitet sie auf. Bei dem Client Computer handelt es sich um eine Single-User-Arbeitsstation, die die benötigten Netzwerkfunktionalitäten sowie geeignete Schnittstellen zur Kommunikation mit dem Server bereitstellt. Der Server bearbeitet Aufträge von einem oder mehreren Benutzern, stellt die Netzwerkfunktionalitäten zur Verfügung und unterstützt die Schnittstellen zur Kommunikation mit den Clients.51 Die Kommunikation beginnt in der Regel mit einer Anfrage des Clients, diese wird dann vom Server bearbeitet, und das Ergebnis wird an den Client zurückgeschickt (vgl. Abbildung 1 52).
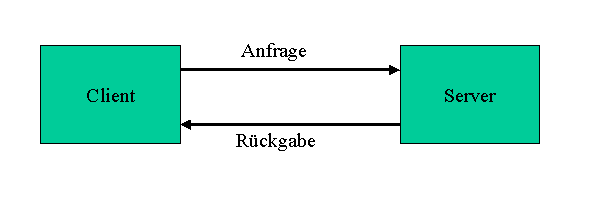
Abbildung 1: Grundschema einer Client-Server-Kommunikation
Eine klare Trennung zwischen Client und Server ist aber nicht immer möglich, da ein Computer sowohl als Server, als auch gleichzeitig als Client auftreten kann. So ist es denkbar, daß ein Client eine Anfrage an einen Server stellt und dieser weitere Daten zur Bearbeitung der Anfrage benötigt, die er nun als Client von einem anderen Server anfordert.
Ein Beispiel für eine Client-Server-Architektur ist das Internet.53 Der Client und der Server benötigen jeweils eine Netzwerkanbindung über ein lokales Netzwerk oder über entfernte Kommunikationsleitungen zum Internet. Als Server agieren häufig Großrechner mit einem UNIX Betriebssystem, und die Clients benutzen in der Regel das Betriebssystem MS-DOS/Windows oder Windows 95. Das Netzprotokoll ist TCP/IP und, wenn zum Beispiel eine WWW-Seite aufgerufen wird, wird das HTTP benutzt. Möchte ein Anwender eine bestimmte WWW-Seite auf seinen als Client agierenden Computer laden, gibt er als erstes die Adresse der WWW-Seite in seinen WWW-Browser ein. Der Browser fordert nun die WWW-Seite von dem Server, der die Seite anbietet, an. Daraufhin bearbeitet der Server diese Anfrage und schickt die Daten der WWW-Seite an den Client. Dieser empfängt die Daten und bereitet sie optisch auf.
Client-Server-Anwendungen lassen sich in zwei Gruppen einteilen, in die Anwendungsmodelle der ersten Generation und die der zweiten Generation.54 Die Anwendungen unterscheiden sich durch die Art, in der Präsentationslogik, Anwendungslogik und Datenzugriffslogik auf Client und Server verteilt werden. Unter der Präsentationslogik versteht man die Art der Realisation der Benutzerschnittstelle. Die Anwendungslogik führt die Verarbeitungsfunktionen durch und übernimmt den Kontrollfluß im System. Die Aufgabe der Datenzugriffslogik ist die Verwaltung der Daten.55
4.1 Anwendungsmodelle der ersten Generation
Bei den Anwendungsmodellen der ersten Generation werden die Logikebenen vertikal zerlegt. Die Präsentationslogik läuft auf dem Client, wohingegen die Anwendungslogik und die Datenzugriffslogik auf dem Server ausgeführt werden. Alternativ hierzu kann auch der Client für die Präsentationslogik und die Anwendungslogik verantwortlich sein und der Server für die Datenzugriffslogik. Zu den Anwendungsmodellen der ersten Generation zählen die klassischen Client-Server-Anwendungen, bei denen die Trennung der Aufgaben in der Gesamtanwendung stattfindet. Die verschiedenen Aufgabenbereiche einer Anwendung werden komplett jeweils dem Client oder dem Server zugeordnet, und Kommunikationen zwischen den Logikebenen finden nur über das Netzwerk statt.
4.2 Anwendungsmodelle der zweiten Generation
Bei den Anwendungsmodellen der zweiten Generation können die drei Logikebenen zu beliebigen Teilen auf Client und Server aufgeteilt werden. So läuft dann jeweils ein Teil der Präsentationslogik, Anwendungslogik und Datenzugriffslogik auf dem Server und der andere Teil auf dem Client. Die Anforderungen an Client-Server-Anwendungsmodelle der zweiten Generation sind: 56
- Rechnerknotenunabhängigkeit (Ortstransparenz)
- Homogenes Verhalten des Systems bei Heterogenität der Hardwareplattformen
- Lauffähigkeit bei Heterogenität der Standardsoftware
- Lauffähigkeit bei Heterogenität der Kommunikationssoftware
- Portierbarkeit der Anwendungskomponenten
- Wiederverwendbarkeit der Anwendungskomponenten
- Erweiterbarkeit und Skalierbarkeit der Gesamtanwendung.
Um diese Ziele zu erreichen, gibt es einige Konzepte, von denen drei im folgenden erläutert werden sollen.
4.2.1 Remote Procedure Call
Eine Möglichkeit, um Client-Server-Anwendungen zu realisieren, sind die sogenannten Remote Procedure Calls (RPC). Hierbei werden einzelne Prozesse auf Client und Server verteilt, wobei es auch möglich ist, Prozesse auf mehrere Clients und Server zu verteilen. Die Verteilung wird meist vom Systemadministrator vorgenommen.57 Die Kommunikation zwischen Client- und Serverprozessen erfolgt über den RPC. RPCs sind vom Client initiierte Funktionsaufrufe, die über das Netz zum Server geleitet werden. Auf dem Server werden die Funktionen gestartet, um dann das Ergebnis über das Netz zum Client zurückzuliefern. Im Netz existiert ein Server, der mit dem Directory Service dem Client eine Aufrufschnittstelle mit einer Vielzahl von Operationen anbietet, man spricht hier vom Export der Schnittstelle. Der Client ermittelt nun mit Hilfe des Directory Services einen Server, der die gewünschte Operation ausführen kann, dieses wird als Import der Schnittstelle bezeichnet.58 Der Client kann die ausgewählte Operation nun lokal aufrufen. Dieser Aufruf wird vom System kodiert, über das Netz an den Server weitergeleitet, vom Server dekodiert und ausgeführt, die Ergebnisse werden kodiert an den Client zurückgeliefert, der sie wieder dekodiert. Grafisch läßt sich die RPC Kommunikation wie folgt darstellen:59
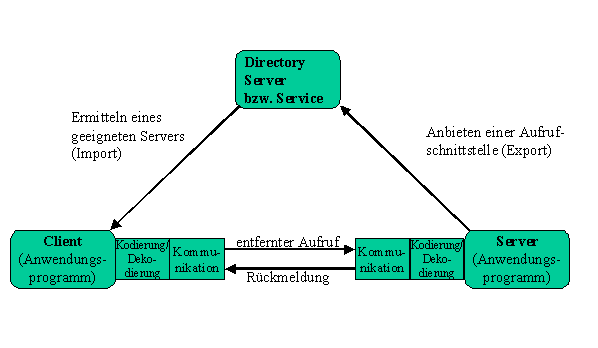
Abbildung 2: Remote Procedure Call
Die Implementierung der RPCs funktioniert folgendermaßen. Damit die Client-Aufrufe den Server-Schnittstellen zugeordnet werden können, wird die Server-Schnittstelle syntaktisch beschrieben.60 Die Beschreibung muß die verwendeten Datentypen, die angebotenen Operationen und alle Parameter umfassen. Für diese Aufgaben kann eine spezielle Beschreibungssprache verwendet werden, oder man kann eine bestehende Programmiersprache um die erforderlichen Elemente erweitern. Beide Möglichkeiten nennt man Interface Definition Language (IDL). Beim DCE-RPC Standard wird die Sprache C erweitert, mit dem Vorteil der Akzeptanz von C und C++ Programmierern und dem Nachteil einer schweren Integration der Beschreibungssprache in andere Programmiersprachen. Man programmiert C-Programme wie für nicht verteilte Systeme für die Client-Seite, auf der Server-Seite sind zusätzlich einige RPC-Initialisierungen vorzunehmen. Da in verteilten Client-Server-Systemen grundsätzlich mit nicht vertrauenswürdigen Systemen gerechnet werden muß, sind Sicherheitsmechanismen erforderlich. Diese können direkt mit dem RPC integriert werden. Es kann eine Authentisierung gebraucht werden, die es Client und Server ermöglichen, sich gegenseitig mit einer verschlüsselten Identifizierung zu erkennen. Mit einer Autorisierung können dem Client Zugriffsrechte auf Server Operationen erteilt bzw. untersagt werden. Eine Verschlüsselung der Kommunikation zwischen Client und Server verhindert das unberechtigte Lesen und Verändern von RPC-Daten.61
Ein großes Problem bei der Benutzung von RPCs ist, daß in der Praxis verschiedene gängige RPC-Standards wie zum Beispiel ONC-RPC, DCE-RPC und ROSE existieren.62 Die RPC-Standards definieren, wie die Mechanismen, die Funktionsaufrufe und Parameterübertragungen zu realisieren sind, es fehlt jedoch die Standardisierung für die Zusammenarbeit verschiedener Applikationen.63 Darum ist es nicht möglich, mit einem verteilten Textverarbeitungsprogramm auf ein verteiltes Datenbanksystem verschiedener Hersteller mit RPC-Aufrufen zuzugreifen.
4.2.2 Verteilte objektorientierte Systeme
Das Grundkonzept der RPCs als Basis für Client-Server-Anwendungen kann erweitert und verbessert werden. Eine Erweiterung ist die Integration der objektorientierten Programmierung. Daraus sind die verteilten objektorientierten Systeme entstanden. Bei verteilten objektorientierten Systemen ist die Datenabstraktion gewährleistet, da auf die Objekte nur mit Schnittstellenoperationen zugegriffen werden kann. Außerdem hat man die Möglichkeit, zusammenhängende Programmteile zu einer Klasse zusammenzufassen. Hiermit lassen sich neue Klassen durch Vererbung von existierenden Klassen erstellen. Über das Netz werden nun Objekte anstatt wie bei den RPCs Operationen aufgerufen, die miteinander kommunizieren. Im Vergleich zu den RPCs ergeben sich folgende Vorteile:64
- Objektverteilung: Auf Client und Server werden nicht mehr relativ große Operationen abgelegt und ausgeführt, sondern kleine Objekte, die Datenstrukturen mit den zugeordneten Operationen enthalten. Objekte können beliebig auf verschiedene Rechner verteilt werden und mit Hilfe von Objekterzeugungsoperationen aufgerufen werden.
- Lokationsunabhängige Aufrufe: Objekte können unabhängig von ihrer momentanen Lokation von anderen Objekten aufgerufen werden. Dabei spielt es keine Rolle, ob das aufrufende Objekt sich auf dem gleichen oder einem anderen Rechner befindet.
- Objektmigration: Objekte können dynamisch während der Laufzeit zwischen Rechnern verlagert werden. Dazu existiert eine spezielle Migrationsoperation, die von einer Anwendung aufgerufen werden kann. Es ist damit zum Beispiel möglich, die Lastenverteilung im Netz zu regulieren.
Durch die weite Verbreitung objektorientierter Programmiersprachen sind die verteilten objektorientierten Systeme zur Client-Server-Kommunikation interessant, da die verwendeten Programmiertechniken für lokale Programme zur Erstellung verteilter Programme benutzt werden können.65
4.2.3 Common Object Request Broker Architecture (CORBA)
Eine andere Ausprägung der Client-Server-Anwendungen ist der Common Object Request Broker. Mit CORBA soll die Bindung der Objekte an eine Programmiersprache beseitigt und die Möglichkeit gegeben werden, über Rechner- und Betriebssystemgrenzen hinweg objektorientierte Komponenten uneingeschränkt zu nutzen.66 Die Entwicklung von CORBA wird von der Object Management Group (OMG), einer Non-Profit-Organisation, geleitet. Sie hat viele namhafte Mitglieder wie Sun Microsystems, Digital Equipment Corporatione, NCR und Hewlett-Packard.67 Die Organisation verfolgt das Ziel, die Portabilität, Wiederverwendbarkeit und Interoperabilität von Software zu maximieren und einen Industriestandard für den Zugriff auf Netzobjekte zu schaffen. Als erstes Ergebnis der OMG wird die Object Management Architecture (OMA) veröffentlicht. Die OMA ist die Basis-Architektur für die Zusammenarbeit von verteilten Objekten. Der Kernbaustein ist der Object Request Broker (ORB).68
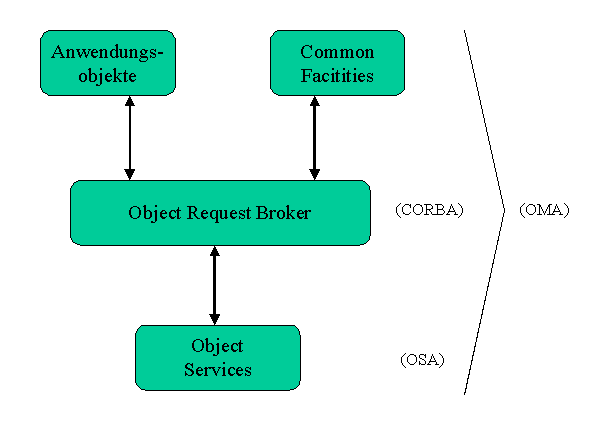
Abbildung 3: Object Management Architecture
Die Object Management Architecture besteht aus den vier Teilen Application Objects, Common Facilities, Object Request Broker (ORB) und Object Services.69 Der Zusammenhang zwischen den Teilen kann aus obiger Grafik entnommen werden.70 Application Objects können die Common Facilities nutzen, indem sie einen Request an diese Objekte schicken. Requests bestehen aus einem Operationsnamen und null oder mehreren Parametern. Die aufrufenden Application Objects können nicht erkennen, von welcher Maschine im Netzwerk der Request bearbeitet wird und welche spezifischen Eigenschaften diese Maschine hat. Um dieses zu gewährleisten, stellt der ORB die Mechanismen dazu zur Verfügung. Der ORB regelt die Zusammenarbeit von Objekten auf verschiedenen Rechnern, unabhängig von Rechner- und Netzwerkarchitektur und der benutzten Programmiersprache.71 Damit die Funktionen in heterogenen Netzwerken genutzt werden können, bietet der ORB unter anderem folgende Dienste an:72
- Der Name Service erlaubt es, Objekte im Netzwerk eindeutig zu benennen.
- Der Request Dispatch Service stellt für jeden Request fest, welche Methoden in welchen Objekten aufgerufen werden müssen.
- Das Parameter Encoding wandelt die Parameterübergaben von einer maschinenspezifischen Darstellung in eine Netzwerkdarstellung um und umgekehrt. Dieser Dienst ist unbedingt bei heterogenen Netzen nötig.
- Der Delivery Service ist für eine korrekte Zustellung von Requests und Ergebnissen sowie die Synchronisation paralleler Anfragen zuständig.
- Der Activation Dienst erfüllt eine Verwaltungsfunktion, die vor dem Aufruf einer Methode den aktuellen Status ermittelt und nach dem Aufruf sichert.
- Der Exception Handling Dienst dient dazu, Ausnahmensituationen zu behandeln, wie zum Beispiel einen Rechnerausfall.
- Die Security Services ermöglichen eine eindeutige gegenseitige Identifikation der Kommunikationspartner.
Durch diese Dienste und Funktionen wird der ORB zur Kommunikationsschaltzentrale der Object Management Architecture. Der ORB hat starke Ähnlichkeiten mit den RPCs, und einige ORB-Realisationen bauen auf dem RPC Dienst auf.73
Die Object Services bieten Basisfunktionen zur Verwaltung von Objekten im Netzwerk an. Darunter befinden sich unter anderem alle Funktion zur Erzeugung und Verwaltung von Klassen und Instanzen, sowie die Möglichkeit, bei Bedarf persistente Objekte zu erzeugen.74
Common Facilities bieten Funktionen, die von mehreren Applikationen gebraucht werden können. Sie sind mit den C++-Class-Librarys oder den Standard Java Packages vergleichbar. Es können von den Common Facilities zum Beispiel Hilfsfunktionen, Druckfunktionen und Datenbankfunktionen angeboten werden. Durch die Nutzung der Common Facilities kann der Entwickler von Netzwerkanwendungen viel Zeit sparen.75
Zu den Application Objects zählen alle Anwendungen, die auf der Basis der OMA Dienste anbieten bzw. das OMA System benutzen. Programme, die diese Architektur verwenden können, sind zum Beispiel CAD-Anwendungen, CASE-System und Netzwerk-Management-Anwendungen.
Zu dieser allgemeinen Definition der OMA existiert eine verbindliche konkrete Definition des Standard-Interfaces und der Architektur eines ORBs, die Common Object Request Broker Architecture (CORBA), die zur Zeit in der Version 2.0 vorliegt.76 Mit dieser Version soll in absehbarer Zeit das Problem gelöst sein, daß ORBs verschiedener Hersteller nicht miteinander kommunizieren können.77 Ein Bestandteil von CORBA ist die standardisierte Interface Definition Language (IDL), die das Interface einer Klasse definiert. Die Beschreibung des Interfaces wird kompiliert und macht eine Klasse für den ORB sichtbar. Des weiteren beschreibt CORBA, wie ein Objekt Methoden anderer Objekte aufruft, egal ob die Objekte lokal oder auf einem entfernten Rechner liegen.78
Bei CORBA gibt es auf der Clientseite zwei Wege, um ein bestimmtes Objekt aufzurufen. Es existieren ein sogenanntes Stub-Interface, das spezifisch für ein Objekt ist, und ein generisches Interface, das dynamisch die Konstruktion von Methodenaufrufen beliebiger Objekte ermöglicht. Das Stub-Interface ist vergleichbar mit der RPC-Schnittstelle. Mit der dynamischen Schnittstelle hat ein Client die Möglichkeit, während der Laufzeit die Schnittstellenbeschreibung eines Objektes zu erfragen und mit dem Ergebnis einen Aufruf einer Methode dieses Objektes zu erzeugen. Der Vorteil des generischen Interfaces ist, daß der Client keinerlei Informationen über das aufzurufende Objekt benötigt.
Die CORBA-Definitionen sind so allgemein gehalten, daß verschiedene ORB denkbar sind. Dadurch ist es möglich, bestimmte ORB sehr effizient zu realisieren.79 Da eine bestimmte Schnittstelle zum ORB wünschenswert ist, wird in der CORBA-Definition der Basic Object Adapter (BOA) beschrieben.80 CORBA verlangt, daß ein BOA in jedem ORB vorhanden ist.81 Er bietet Funktionen zur Erzeugung, Verwaltung und Interpretation von Objektreferenzen. Außerdem identifiziert und authentisiert er jeden aufrufenden Client und aktiviert und deaktiviert
die Implementationen. Das heißt, daß dauerhafte Objekte auf Speichermedien abgelegt werden müssen. Bei einer Aktivierung ist die Aufgabe des BOA, den Zugriff auf diese Objekte zu erlauben, und bei der Deaktivierung müssen die modifizierten Informationen wieder zurückgeschrieben werden. Die Beschreibung der Schnittstellen der Aufrufe werden in CORBA mit einer Interface Definition Language (IDL) vorgenommen. Mit der IDL-Beschreibung einer Klasse werden Methoden, Parameter und eventuell auftretende Ausnahmebedingungen beschrieben. Die IDL ähnelt der Programmiersprache C++. CORBA legt fest, wie die IDL auf verschiedene Programmiersprachen wie C, C++, Smalltalk oder Java abgebildet wird.82
Nach dieser kurzen Einführung in CORBA erkennt man schon, daß CORBA viele Vorteile gegenüber anderen Architekturen von verteilten Systemen besitzt. Der größte Vorteil ist darin zu sehen, daß viele namhafte Firmen der OMG angehören und es zukünftig eventuell dazu kommt, daß CORBA zu einem Industriestandard wird. Ein Problem ist, daß die zur Zeit verfügbaren CORBA ORBs langsam und ineffizient sind.83 Verfügbare ORBs sind unter anderem ORBIX von Iona, Objectbroker von Digital, System Object Model (SOM) von IBM, ORB Plus von Hewlett Packard und Distributed Objects Everywhere (DOE) von Sun.84 CORBA bekommt eine besondere Bedeutung durch das größte heterogene Netzwerk der Welt, dem Internet, und durch die objektorientierte Internet-Programmiersprache Java. Durch eine Verknüpfung von CORBA und Java können Programme für Internet- und Intranetserver programmiert werden, die mit Applets auf verschiedenen Rechnern kommunizieren und auf Datenbanken zugreifen können.85 Außerdem können Programme, die mit anderen Sprachen programmiert werden, mittels CORBA in Java-Programme integriert werden.
